KV Cache on SSD: Taking Twitter's Fatcache as an Example.
High performance in-memory key-value caches are indispensable components in large-scale web architecture. However, the limited memory capacity and high power consumption of memory motives researchers and developers to develop key-value cache on SSD, where SSD is considered as an extension of limited memory.
In this post, I will talk about the general ideas about KV cache on SSD based on Twitter’s fatcache and further discuss the issues with this traditional approach.
Background
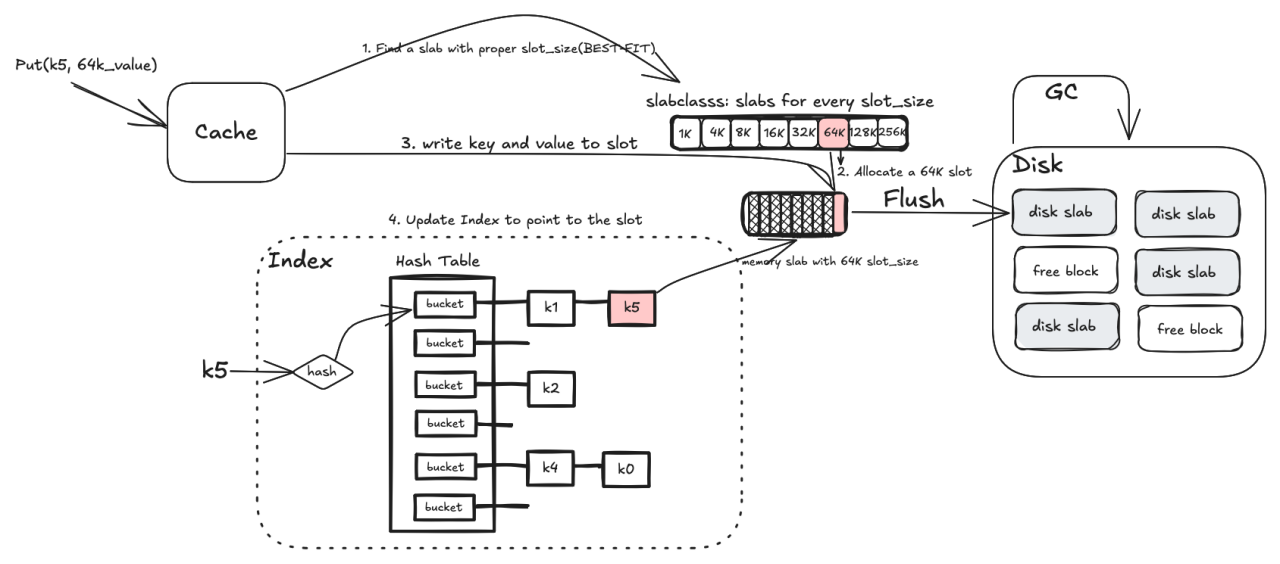
Twitter’s fatcache and many other modern memory allocators, such as Google tcmalloc and Linux slab allocator are based on the idea of slab allocator. You can get the comprehensive detail about slab allocator in paper titled The slab allocator: An object-caching kernel memory allocator. I am not willing to delve into too many trivial details here, but overall, slab allocator is a kind of segregated list list allocator. The term slab is actually a continuous memory area, which is the basic management unit of slab allocator. A slab is further divided into slots of the same size which are used to store objects and other metadata. Besides, a slab uses a freelist to keep track of the allocation status of slots, which is the key of allocation and deallocation. All slabs with the same slot(object) size are categorized together and further organized into a sorted array based on the slot size. By doing so, the allocator is able to use binary search to allocate objects from the best-fitted slab.
![Featured image for [Paper Note] ALPS An Adaptive Learning, Priority OS Scheduler for Serverless Functions](/posts/alps-an-adaptive-learning-priority-os-scheduler-for-serverless-functions/images/alps-figure-2.png)
![Featured image for [Paper Note] Demystifying and Checking Silent Semantic Violations in Large Distributed Systems](/posts/demystifying-and-checking-silent-semantic-violations-in-large-distributed-systems/images/demystifying-and-checking-silent-semantic-violations-in-large-distributed-systems-architecture.png)
![Featured image for [Paper Note] Understanding, detecting and localizing partial failures in large system software](/posts/understanding-detecting-and-localizing-partial-failures-in-large-system-software/images/understanding-detecting-and-localizing-partial-failures-in-large-system-software-figure-4.png)